Chaotic First Post of 2019¶
Published on 2019-04-03
This is the hopefully better-late-than-never first post of the great new year of 2019. It’s been a long time since my last post here. For several months, I was playing around with a lot of new ideas and was more comfortable doing short updates on Mastodon. That has settled down a bit and my focus for 2019 is set.
Much has happened, so this Chaotic First Post of 2019 is a good way for me to organize the jumbled events of the past year and reflect on them.
2018: What I Did in Tech¶
Game Engine and Graphics Programming¶
In early 2018, I began creating my first game engine using Python/OpenGL and participated in the OGAM game jam for a few months. I wrote about that extensively on this blog. Writing a game engine was a great way to build more experience with geometry and matrix operations in computer graphics. Python was a great prototyping engine for ideas. Through that project, I came to really appreciate Python as a prototyping tool. That’s not to say it’s not appropriate for production. I think it is, in its domains. But I think it really shines for iterating over designs quickly (I also used Python to start the vale8x64 assembler, but more on that another time).
When adding support for particle systems, I noticed some frame rate issues with the engine and did several rounds of performance optimization. I think I could have continued to optimize and develop the engine in Python for quite awhile, had I moved engine code into a separate thread and re-evaluated some design decisions. But it was too late; I had started learning Rust and was eager to use it.
I managed to port much of my engine code to Rust in my first few weeks of learning it. I was impressed with the maturity of the available libraries (crates), the quality of the documentation, and the helpfulness of the community to beginners. But I quickly learned that certain fundamental data structures and patterns are difficult to implement in safe Rust. Examples from my engine include the entity graph, a tree-like structure used to store and manipulate game object state, and the callback-based global event system. Nonetheless, I enjoyed using Rust and learned to either make the extra effort or drop into unsafe Rust to work around these issues.
Emulation¶
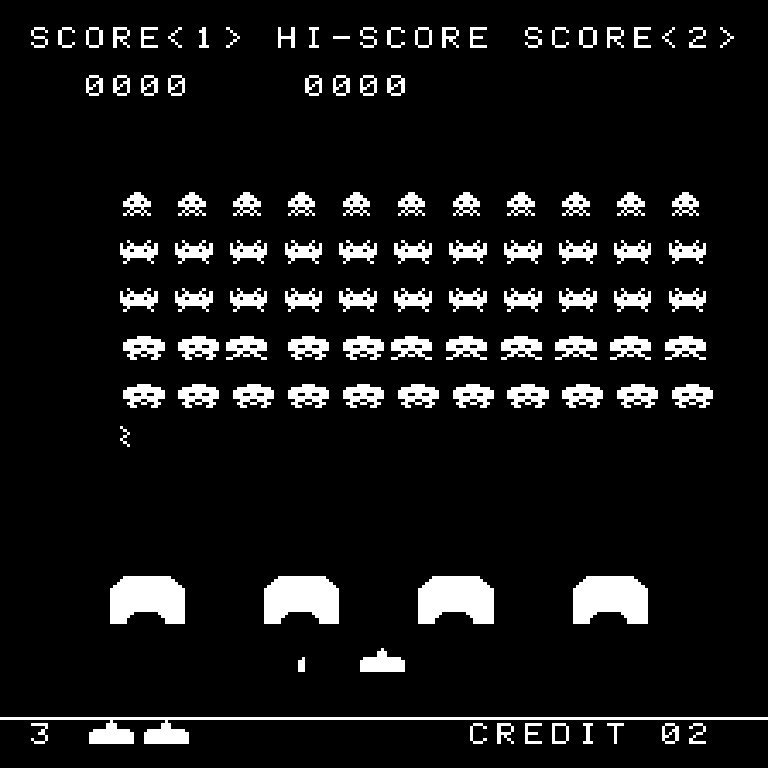
After learning basic Rust and porting the game engine, I discovered and followed the Emulator 101 series, using Rust instead of C, and created a Space Invaders emulator. This was my first foray into emulation, and it really hooked me.
Looking for another emulation fix, I went on to create a partial Game Boy emulator in Rust.

There was something about emulation that felt fundamentally cool, but also felt novel and, in certain ways, unlike other programming I’d done before.
Abstractly and briefly, making software emulation is about learning the implementation details of some system, and then writing software to reproduce the behavior of that system as closely as is practical and necessary.
I wonder if it stimulates the brain in the same way as world-building activities and simulation/building games. That’s kind of what doing emulation feels like to me.
This new and exciting area came with a set of unique challenges that can make it very difficult.
The specifications of the target system may not be well-defined enough to emulate. For example, a CPU’s reference manual may have incomplete or incorrect documentation of an instruction’s behavior (I’m looking at the DAA instruction on the Game Boy processor, and this guy had the same problem; it’s common).
Likewise, a CPU instruction could have bugs in corner cases where it doesn’t behave as defined. But software for the system may rely on those bugs being there. From memory, I think I had this problem with the DAA instruction on the Intel 8080, but I’m not certain.
In either of the above cases, you could implement the instruction with correct logic, as defined in whatever documentation you have, but get unexpected results in emulation. A popular system is likely to have existing emulators and a community behind it to help. If you were emulating an exotic piece of hardware and no prior work were available to reference, one solution to this problem might be to get a working unit, write test cases for all known inputs to the problematic routine, and work out the behavior by analyzing the outputs.
Another challenge of emulation is that potential documentation gaps and idiosyncratic behavior in the target system can make it difficult to write a thorough set of test cases to verify the expected behavior. The best pre-existing test cases may be complete programs that require a large part of the system to be emulated correctly to do anything interesting. Until you get there, you can step through one instruction at a time with your disassembler and compare the system state with that of another emulator, if available.
Emulation has influenced my view on proprietary hardware and software systems (as opposed to free/libre ones). There was a magical feeling juxtaposed with the tedium of debugging as I used the disassemblers I wrote for these processors to step through the Space Invaders and Dr. Mario programs. In retrospect, I was developing a new perspective on “openness”: with sufficient knowledge and methods of observation, using the words “proprietary” or “closed” to describe a system is meaningless. All human-made systems obfuscated either intentionally or by omission of information are eventually reverse engineered using the same methods and tools we’ve used to learn the mechanisms behind natural phenomena. In this sense, can the implementation details of a system be the “secret” property of any person or other entity, any more than undiscovered secrets of nature are property of the universe? The legal system around intellectual property adds gray color to this black and white shift in my perspective, and has raised ethical implications I continue to think about. I want to discuss and debate this.
Homebrew Computers¶
In the background during all this, I was working through the All About Circuits textbook and assembling the experiments. Things became really interesting when I got to the digital section and starting learning about semiconductors and digital logic.
I found TTL computers like the Gigatron and Ben Eater’s 8-bit breadboard computer. After several months of working on 8-bit emulators and building small breadboard projects, creating a hardware CPU seemed like a natural next step. I ordered a lot of 7400 series TTL logic ICs from Ali Express and went through most of the material in Digital Computer Electronics (Malvino and Brown) thoroughly, careful to do each exercise and completely understand each logic circuit in the book. As the 7400 parts came, I used Eater’s tutorials and the schematics from the DCE book to do a partial CPU implementation on breadboards. That was the start of vale8x64, the major project of 2019 which I’ll review in more detail in a future post.

2018: Things I Learned¶
More Comfort in Inexperience¶
Sort of. In 2018, I was uncomfortable developing my projects in public repositories, self-conscious to show my low-quality prototypes and inexperience in the new domains where I’ve chosen to put my time lately. I thought I’d get each project finished (whatever that means), and then to some admirable state of quality, and then release it under a libre license. I’ve realized some things that have changed my habits recently.
It’s irrational to be self-conscious about publishing my work in new areas. Few people are likely to use their time to look at what I’ve pushed to gitlab. If anything I do becomes significant enough that the way I did it is problematic, that’s an okay problem.
It’s not productive to wait for mastery of a domain before trying to contribute in its community. There’s always more to know. There is more than one topic in which any person is a novice for each topic in which that person is an expert. That will be the case for every person’s natural life. Thus, it makes sense to make an effort to contribute at all skill levels. This is part of having a growth mindset.
Developing in public is a great way to improve skill in a new area. More experienced people are happy to hone their experience by taking time to do design and code reviews for novices.
Releasing early is a great way for me to practice quality. If no one else is looking, it’s tempting to ignore proper error handling, memory management, and other good practices perpetually, promising to do it later (I’ve started to call this arrangement “practicing prototyping”). On the other hand, if someone else can see my work, I’m motivated to show my best work. The larger a project grows without attention to all the fine details, the larger the effort required to retroactively address those details when they matter; prototyping for too long puts the quality of the product at risk. So committing to frequent and early releases of whatever slice of functionality I make is a great motivator to practice good habits throughout the development lifecycle.
Feeling Stupid Is Good¶
Put less bluntly, I’m becoming less likely to feel inadequate or frustrated when I’m unable to understand a topic or complete a task easily, and more likely to see it a signal that I’m expanding the limits of my capabilities. Said a different way, I’m getting better at re-framing discouragement as motivation. It seems like an obvious thing when I view it in writing, but is a perspective shift for me regardless.
More Politics?¶
Privacy and software ethics concern me more and more. As I see privacy become more intertwined with the “data economy”, and service providers’ abuse of users and customers become more bold and pervasive, my position against proprietary (obfuscated) software and hardware becomes more extreme. I initially wanted to keep my ‘net presence purely technical, but I may re-evaluate that and start to write more about tech politics at some time.
Bye¶
Thanks for reading my 2018 retrospective. In the next post, I’ll talk more about building homebrew computers and give an overview of the vale project.
If you found any of this post interesting, valuable, or debatable, I’d enjoy the conversation.
Social and Mastodon¶
In 2018, I made an effort to make frequent short-form updates on my projects. I chose to make my updates on Twitter, Mastodon, and Instagram.
Suffice it to say that I’ve found a great home on Mastodon (specifically, on the Fosstodon instance). I’m impressed with the user experience on the fediverse. I’ve met other hardware enthusiasts and other interesting people and am happy to have found an instance where I can network with other Free/Libre advocates. I still post to the other platforms, but the majority of my social networking is on Mastodon, and I expect that to be the case for 2019 and beyond.
If you’re interested in building community on decentralized services, I recommend Mastodon. It’s now my preferred contact method, along with email.